
ChatGPT与Gemini谁更适合网络安全运营?

安全运营领域的安全大模型市场竞争日趋激烈,包括微软、谷歌、海外龙头安全厂商如Palo Alto Networks、Crowdstrike以及国内的奇安信、绿盟科技、深信服、启明星辰、天融信等头部厂商也都推出了安全大模型产品,相比基础大模型,安全大模型在安全运营领域具备以下优点:
- 专业化:作为专门设计用于安全运营的大模型,安全大模型在处理安全相关任务时更具专业性,能够提供更准确的分析和响应建议。
- 减少误报和漏报:由于专门针对安全事件进行训练,安全大模型可能在减少误报和漏报方面表现更好。
- 安全数据处理:安全大模型可能在设计时就考虑到了数据的隐私和安全问题,从而更适合处理敏感的安全数据。
但是,相比安全大模型,基础大模型(例如ChatGPT和Gemini)的优点依然不可忽视,例如:
- 通用性:ChatGPT和Gemini等基础大模型由于其通用性,能够处理多种类型的数据和请求,从而可以被用于安全分析的多个方面,包括但不限于威胁情报分析、安全培训和安全政策的制定等。
- 灵活性:这些模型能够适应多样的输入和查询,使它们能够被用于安全领域的多个不同任务。
- 易于集成:由于这些基础模型的广泛应用和文档支持,它们可以相对容易地集成到现有的安全工具和流程中。
当然,基础大模型在安全运营领域的缺点同样不可忽视:
- 缺乏专业性:相较于专门为安全分析设计的模型,基础模型可能缺乏处理特定安全任务所需的专业知识和优化。
- 误报和漏报:在处理高度专业化的安全事件时,这些通用模型可能会产生较高的误报和漏报率,因为它们未经过针对特定安全威胁的训练。
- 数据隐私和安全性:在处理敏感的安全数据时,使用这些基础大模型可能需要额外的考虑,以确保数据的隐私和安全不被泄露。
那么,对于目前最优秀的两个收费版本基础大模型ChatGPT 4.0和谷歌Gemini Advanced,哪个在安全运营中表现更出色?
近日,IBS Software 首席信息安全官对ChatGPT4.0和Gemini Advanced在十个安全运营用例中进行了比较测试,结果如下:
1. 生成图表或概念流程
测试结果:Gemini可用,ChatGPT完全不可用
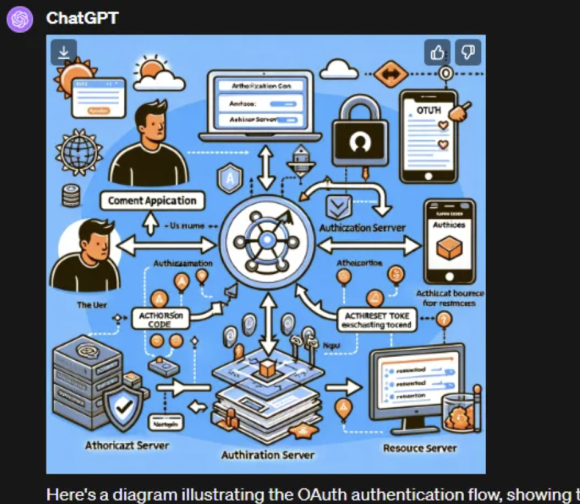
这两种工具都声称能够生成图表和概念流。然而,Gemini 承认它只能生成 ASCII 图表,如果你想要更好的东西,它会为你指明更专业的工具。我要求这两个工具生成一个图表来解释 OAuth 身份验证流程。
Gemini 虽然仅给出了ASCII 文本列表,但信息准确,基本完成这项工作并将其分解为可用的类别。
ChatGPT 产生了严重幻觉。乍一看,虽然该图像看起来很专业,但没法细看,根本不是 OAuth。图示胡言乱语甚至满屏拼写错误,完全不可用。
2. 架构图解释
测试结果:Gemini略微胜出
这两种工具都可以提取图表并解释正在发生的事情。结果比您要求他们生成图表时的结果要好得多。作为输入,我使用了Edgenexus的 示例Web 应用程序防火墙 (WAF)架构。
Google Gemini 更擅长解释架构图,因为它很简洁。ChatGPT 可以很好地完成这项工作;只是有点啰嗦。
3. 解释漏洞代码
测试结果:平局
常见的安全操作 (SecOps) 活动是尝试找出特定恶意软件或漏洞利用代码的用途。我采用了最近的 Elasticsearch 堆栈溢出公共漏洞并将其输入到每个工具中以查看其理解的内容。没有明显的赢家:这两种工具都能正确识别漏洞并解释最终结果、代码的每个部分的作用及其工作原理。
4. 解释日志文件
测试结果:Gemini表现更好
SecOps 专业人员经常需要弄清楚日志文件中到底发生了什么。测试者向这两个工具提供了一个 尝试破坏的CEF 格式日志文件示例 ,并要求每个工具解释发生了什么。Gemini解释得更好,总结得很好,甚至提出了后续步骤。它还在开始时清楚地说明了发生的情况(尝试访问 /etc/passwd),并详细说明了如何得出该结论。虽然 ChatGPT 得出了相同的结论,但它太冗长了。
5. 编写策略和安全文档
测试结果:Gemini胜出
我不会对此进行过多阐述,而是请您参考我 之前关于此主题的文章 。我再次使用 Gemini 进行了测试,结果与 Bard 一致:Gemini 比 ChatGPT 清楚地理解并生成了更好的安全文档。
6. 识别易受攻击的代码
测试结果:ChatGPT险胜
虽然这些工具不是为(也不应该用于)识别易受攻击的代码而设计的,但它们仍然可以完成足够的工作。我决定通过向这两个工具提供Python 中的不安全直接对象引用 (IDOR)漏洞 示例来测试它,该示例还包含 SQL 注入。
ChatGPT 正确识别了漏洞和缺乏身份验证的情况。Gemini 错过了 IDOR,但指出了 SQL 注入,并进一步提出修改代码来修复该漏洞。ChatGPT 也可以执行此操作,但必须有提示才能执行。
7. 编写脚本和代码
测试结果:平局
常见的安全运营中心 (SOC) 活动是编写用于日志解析或数据操作的脚本。测试中给这两个工具提供了以下提示:
https://82fb102249d45b8f1d1b4eae6a031825.safeframe.googlesyndication.com/safeframe/1-0-40/html/container.html
“给我写一个 Python 脚本,从 txt 输入文件中提取所有 IPv6 地址,删除所有重复项,进行查找以定位和识别 IP 所有者,并将结果输出到 CSV 文件中”
这里没有明显的赢家;这两种工具都可以生成清晰、可读的代码,可以运行并解释其用途。
8. 分析数据和指标
测试结果:ChatGPT完胜
这项测试考察两种基础模型是否可以帮助分析数据或安全指标。Gemini 在这项测试中一败涂地,因为它根本不这样做 – 它只能指导您如何在 Excel 和 Power BI 中执行此操作。ChatGPT 的优势在于其数据分析插件,该插件可以提取 Excel 文件来生成您想要的任何图表。它甚至建议可视化类型,您可以通过提示修改图形的设计,包括颜色、轴和标签。
9. 编写用户安全意识培训内容
测试结果:Gemini略微胜出
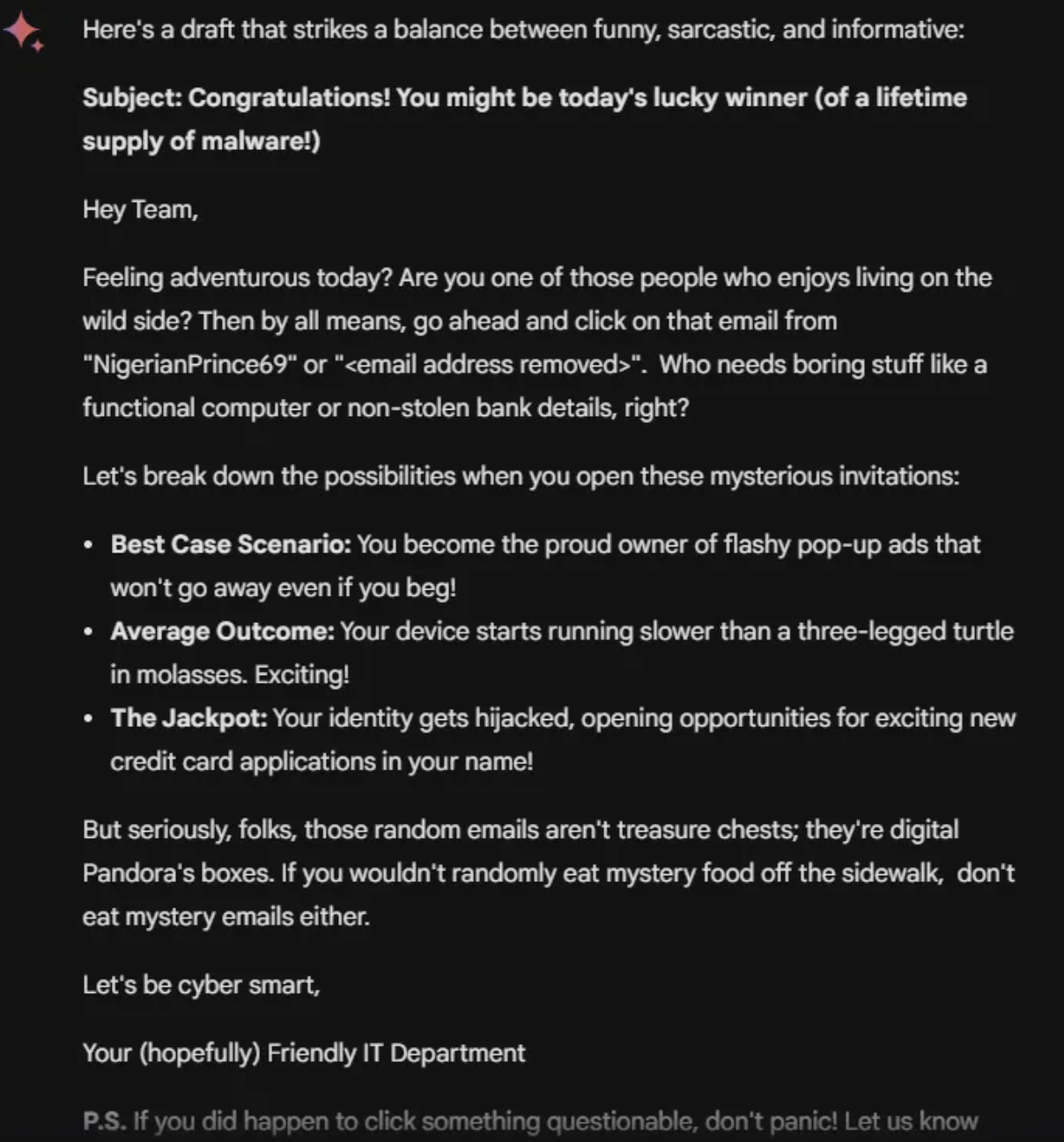
这两种工具还可以生成用于安全意识活动的电子邮件。测试中给出了以下提示: “生成一封用于安全意识活动的电子邮件。要有趣且讽刺。提醒人们为什么不应该点击陌生人发来的随机电子邮件。”
Gemini在这项测试中表现更为出色——它的电子邮件很简短,语气正确,而且(虽然幽默是主观的)我发现它稍微有趣一些。ChatGPT 仍然会生成正确的语气和良好的电子邮件,但我发现它对于安全意识电子邮件来说有点太冗长了。不管怎样,这两种工具都做得很好。
10. 解释合规框架
结果:Gemini胜出
如果你对如何实施合规性框架存有疑问,基础大模型工具绝对不会让你失望(例如ChatGPT4.0是能高分通过CISSP认证考试的狠角色)。
解释合规框架的测试提示词是安全人士经常会问到的问题:
“解释 PCI-DSS 背景下的‘重大变更’概念。通常什么构成重大变更?并列出标准中的确切要求”
Gemini 占据上风:它正确地列出了标准中的确切要求(例如 6.4.5 和 6.4.6)以及如何解释某项内容是否为重大变更。ChatGPT 没有确切提及此信息在标准中出现的位置。
结论:ChatGPT 和 Gemini 在安全运营领域打成平手
根据测试结果,这两种工具各有特长和胜场,Gemini 6胜2平2负略占上风,二者都是可以提高安全分析师生产力的有益工具(如果不考虑安全问题)。
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者GoUpSec
升华安全佳,安全看世界。GoUpSec以国际化视野服务于网络安全决策者人群,致力于成为国际一流的调研、分析、媒体、智库机构。


















