
DeepSeek炸街美股,英伟达哭了,苹果赢麻了?
当中国AI新秀DeepSeek带着“557万美元训练成本暴打OpenAI”的剧本杀入科技圈,全球股市瞬间上演了一场《鱿鱼游戏》真人版——英伟达市值一夜蒸发4万亿,而苹果却成了最大赢家,股价逆势上扬。
英伟达哭昏,苹果躺赢
被中国网友戏称为“皮衣刀客”的黄仁勋做梦也没想到,会被DeepSeek的一句“用H800就能跑”破了大防。毕竟,硅谷大佬们曾坚信“没有最贵的GPU,只有更贵的模型”,结果DeepSeek反手掏出成本仅OpenAI零头的R1模型,直接让英伟达股价表演“高空跳水”——单日暴跌17%,创下美股史上最大单日市值蒸发纪录(约4万亿人民币)。
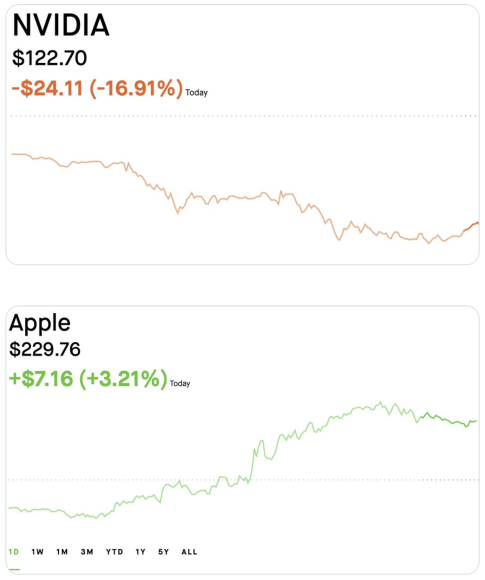
就在硅谷一片哀嚎时,苹果股价逆势狂飙3.25%,市值重回3.5万亿美元,库克微微一笑:“感谢同行衬托。”原来,DeepSeek模型意外暴露了苹果M系列芯片运行大模型的超高性价比。
以下是当前市场上支持DeepSeek V3和R1运行的主要芯片及其性能和价格的详细比较:
| 芯片型号 | 内存容量 | 内存带宽 | 价格 | 每GB成本 |
|---|---|---|---|---|
| NVIDIA H100 | 80GB | 3TB/s | $25,000 | $312.50 |
| AMD MI300X | 192GB | 5.3TB/s | $20,000 | $104.17 |
| Apple M2 Ultra | 192GB | 800GB/s | $5,000 | $26.04 |
苹果M2 Ultra芯片(于2023年6月发布)每GB内存的成本效益比AMD MI300X高出4倍,且比NVIDIA H100高出12倍!
DeepSeek V3和R1是稀疏专家模型(MoE,Mixture of Experts),拥有 6710亿参数,但每次生成一个token时只需激活 37亿参数。由于无法事先确定哪些参数会被激活,所有参数都需要时刻准备在高速显存中,以实现高效的运行性能。
- 传统内存不足以满足需求: 系统RAM的加载速度过慢,无法满足每秒生成一个token的需求。
- 显存价格昂贵: 尽管GPU显存速度快,但其成本非常高。
苹果通过 统一内存(Unified Memory) 和 UltraFusion 技术,为DeepSeek的运行需求提供了独特且经济高效的解决方案。
苹果的技术优势
- 统一内存(Unified Memory):
苹果的统一内存架构将CPU和GPU共享的内存池整合在一起,无需单独配置内存或在CPU与GPU之间复制数据。这种设计极大地减少了数据传输的开销。 - UltraFusion技术:
UltraFusion是苹果的专有互联技术,通过超高速、低延迟的连接(2.5TB/s)将两个M2 Max芯片整合为M2 Ultra。此技术实现了更高的内存容量(192GB)和更快的内存带宽(800GB/s)。 - 下一代M4 Ultra的潜力:
据传,M4 Ultra将通过UltraFusion连接两块M4 Max芯片,达到 256GB统一内存 和 1146GB/s内存带宽。两块M4 Ultra将能够以 每秒57个token 的速度运行DeepSeek V3/R1(4位精度)。
DeepSeek的MoE模型需要高速内存随时待命,而苹果的“内存大锅饭”策略(统一内存架构+UltraFusion胶水黑科技)完美适配——既不用像英伟达那样“拆东墙补西墙”倒数据,还能用白菜价实现“内存自由”。网友辣评:“库克这波叫‘用魔法打败魔法’!”

更绝的是,苹果一位机器学习工程师(@awnihannun)甚至用7台M4 Mac Mini(上图)组队成功运行了满血版的DeepSeek R1模型(6710亿参数),活生生把AI算力从机房玩到了桌面。难怪极客们惊呼:“苹果这是要革GPU的命啊!”
炼丹设备快速通道:
- MacBook Pro 14英寸M4 Max(64GB)京东购买链接 (到手价格:32249元)
- M2 Max(64G 1TB)京东购买链接(到手价:19849元)
- M4 Pro(64GB)京东购买链接(到手价:15499元)
- M4 Mac Mini (32GB)京东购买链接(到手价:8249元)
如果你是Windows用户,那么目前运行32B参数的 DeepSeek-r1模型性价比最高的选择依然是3090显卡:
3090英伟达全新涡轮显卡 京东链接 (到手价:7500元)
中美AI大战:苹果坐收渔翁之利
DeepSeek的横空出世,不仅让特朗普高呼“美国要敲响警钟”,还意外揭露了硅谷的“算力内卷”真相——OpenAI烧50亿刀训练模型,谷歌年砸500亿搞基建,结果中国公司靠算法优化和“榨干每一张显卡”的硬核操作,直接实现“弯道超车”。
而苹果则趁机偷家:一边在iOS 18.3默认开启“Apple Intelligence”(禁用翻过车的新闻摘要功能),一边用开源框架MLX和民间大神@exolabs的“Mac Mini集群神教”,把AI算力平民化。网友调侃:“库克这是‘借刀杀人’,用中国AI打美国芯片,自己坐收渔利!”
英伟达反杀M4的终极武器:Project Digits
但是,苹果的幸福来得突然,去的也可能很快!

在苹果通过其统一内存架构将M4芯片定位为本地AI推理的重要硬件时,NVIDIA以其最新的 Project Digits 项目(上图)显著拉低了本地运行尖端大语言模型(LLM)的成本,成为AI硬件市场的新焦点。
Project Digits与苹果M4芯片对比
以下是NVIDIA Project Digits与苹果M4系列设备在关键参数上的性能和价格对比:
| 设备 | 内存容量 | 内存带宽 | 计算性能 (FP16) | 价格 |
|---|---|---|---|---|
| Project Digits | 128GB | 512GB/s | 250 TFLOPS | $3,000 |
| M4 Pro Mac Mini | 64GB | 273GB/s | 17 TFLOPS | $2,200 |
| M4 Max MacBook Pro | 128GB | 546GB/s | 34 TFLOPS | $4,700 |
对比数据显示:
- Project Digits 的 内存带宽 是 M4 Pro 的 2倍,并且拥有 14倍的计算能力。
- 价格仅为 $3,000,相比苹果设备提供了显著的性价比优势。
Project Digits的技术优势
- 高效内存与算力:
- Project Digits 配备 128GB内存 和 512GB/s内存带宽,可在 FP16精度下实现250 TFLOPS 的计算性能。
- 能够以 8 tokens/秒 的速度运行 Llama 3.3 70B(FP8精度),适合阅读速度的AI推理需求。
- 突破内存与带宽瓶颈:
- 传统的消费级显卡(如RTX 4090)受限于显存容量(24GB)和PCIe 4.0接口带宽(64GB/s),无法将整个模型加载到显卡中,导致推理性能被系统RAM到GPU传输速度所限制。
- Project Digits通过提供大容量内存和更高带宽,从根本上解决了这一瓶颈。
- 多GPU集群支持:
- 借助即将推出的 PCIe 5.0接口,用户可以组建多个 NVIDIA 5070 GPU 的计算集群。双GPU配置支持从系统RAM到GPU的 256GB/s带宽,能够更高效地运行大语言模型。
- 支持 CUDA( Apple 不支持);这意味着爱好者可以更轻松地在 Digits 上训练模型。
对苹果的冲击
苹果近年来以M系列芯片的统一内存架构和卓越能效吸引了众多开发者,但与NVIDIA Project Digits的对比表明:
- 性价比劣势: Project Digits仅需 $3,000,远低于苹果高端设备的价格。
- 性能差距明显: 无论是内存带宽还是计算能力,苹果M4芯片都处于劣势。
DeepSeek为英伟达关上一扇门,同时打开了一扇窗
Project Digits的推出不仅让NVIDIA在消费级市场树立了更强的竞争力,还开辟了本地甚至桌面运行尖端AI模型的新市场。随着 @exolabs 宣布将从 发布第一天 开始支持 Project Digits集群 的高性能推理,这一项目的应用潜力进一步得到验证。
NVIDIA的突破预示着一场硬件技术格局的重大变革。Project Digits不仅为本地运行AI模型提供了新的可能性,还进一步巩固了NVIDIA在AI硬件领域的领导地位。
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者Cashcow
隐私已经死去,软件正在吃掉世界,数据即将爆炸


















