
国家不让TikTok卖的到底是个啥
TikTok这出肥皂剧,最新的进展是商务部会同科技部调整发布了《中国禁止出口限制出口技术目录》。这个调整,最直接的影响应该是,字节跳动要想把TikTok整体打包卖给美国企业,必须到省级(北京市)商务主管部门申请技术出口许可,获得批准后方可对外进行实质性谈判,签订技术出口合同。简而言之,TikTok想卖没那么容易了。

这个消息一出,各种吃瓜评论此起彼伏。然而吃了几天的瓜以后,我发现大家都在大国博弈、民族气节这种高举高打的层面上讨论,反而一个关键的问题几乎没人谈论:
问题1:国家不让TikTok卖的到底是什么?
这个问题看似很蠢,不是在《目录》的调整中都说明白了么,增加了“基于数据分析的个性化信息推送服务技术”,就这个技术不让卖嘛。
问题2:那什么是“基于数据分析的个性化信息推送服务技术”呢?
这个问题,就开始有点意思了。因为我们都知道,中国的互联网公司,有一个算一个,基本上是不掌握什么核心科技的,大家都是在开源架构基础上搞搞工程应用。当然工程应用也是非常有价值的东西,但是只要看看美国的实体清单(aka川总选股),中国互联网公司没什么核心技术这一点也就很明显了。
于是这就有了一个矛盾:既然没什么核心技术,为啥中国政府不让卖?这个矛盾的关键就在于前面的问题2:这个“基于数据分析的个性化信息推送服务技术”到底是什么。我在以前的一个文章(用敏捷方法管理机器学习项目:工作内容)里面讲过,建一个机器学习(或者比较潮的说法,“人工智能”)系统,大概就是这么一个过程:
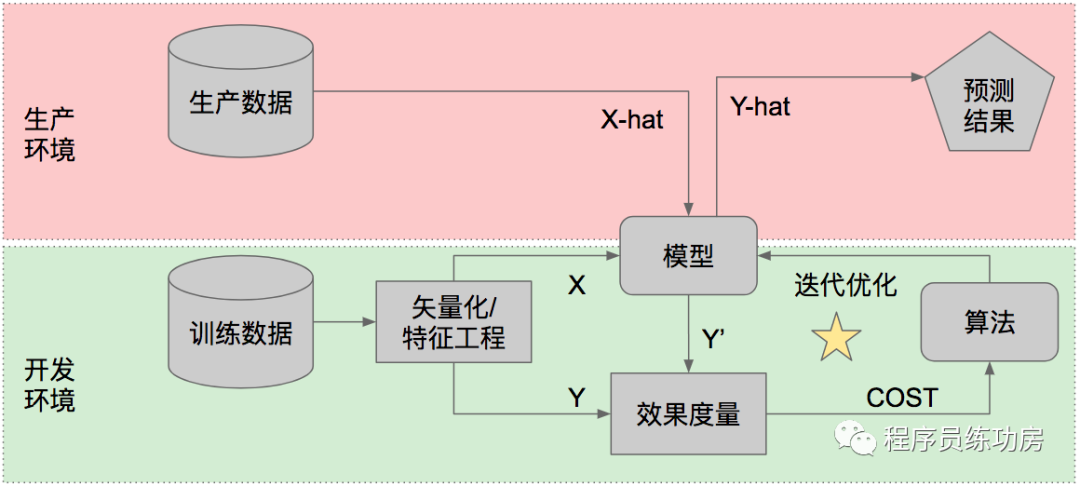
简单说,就是你需要先拿一大堆数据,用一个机器学习的算法来训练,得到一个模型。然后你就可以拿着模型去对新的数据做预测。「用过往的数据训练得到模型」这个过程,是人工智能的开发过程。「用训练好的模型预测未来的数据」这个过程,是人工智能的使用过程。
现在看明白了吗?《目录》里说的“基于数据分析的个性化信息推送服务技术”,不是指训练模型用的算法,而是指训练完成的模型本身。
这就解释了前面这个矛盾:字节跳动使用的算法(我猜测)并没有什么特别的核心科技,无非就是大家都在用的一些推荐算法,大概率都已经发了paper了,顶多加上若干工(tiao)程(can)优(shu)化,这东西不至于让中国政府专门发个公告不准往外卖。真正不让卖的,是这个算法训练出的模型,也就是在抖音和TikTok背后每天做几亿次推荐的那个人工智能。
问题3:为什么模型不能卖给外国企业?
这时候我们才真正接近这个问题的本质:模型到底是什么?
过去计算机行业有一个经典的说法:程序=算法+数据。算法是确定的、放诸四海而皆准的。将不变的算法应用于不断变动、层出不穷的数据,就得到了计算机软件千变万化的行为。这个理论在过去很多年、对于很多软件都是适用的,但对于机器学习/人工智能类型的软件,它就失效了。失效的点,恰好就是这个「模型是什么」的问题。
模型是算法吗?好像是,又好像不是。模型确实(像算法一样)决定着软件的不同行为。但生产环境中使用的模型,其行为很大程度上无法被解释、无法被描述,唯一合适的描述就是「过去是这样的,所以未来也会这样」。从「一系列解决问题的清晰指令」这个定义来说,模型无论如何也不是经典意义上的算法。
模型是数据吗?这就更难回答了。一方面,模型确实来自于过往的数据,甚至可以说,每个用户做过的每个操作,都在模型中留下了痕迹。但另一方面,「训练」是一个不可逆的过程:从模型无法反推出用户的具体信息、具体操作,所有的数据都已经成为了这个人工智能无可分割的组成部分。从这个角度来说,模型又不像是经典意义上的数据。
但信息论告诉我们,一切负熵俱有由来。一个模型能对未来的数据做出比较准确的(优于丢骰子瞎猜的)预测,是因为训练过程中使用的数据为其提供了信息(负熵)。换句话说,字节跳动使用的推荐模型,蕴含了中国几亿用户、几千亿次交互的信息。
的确,从模型中无法还原起初的数据,因此我们并不能简单地说「获得字节跳动的推荐模型就等于获得了中国人的行为数据」。但我们同样不能忽视「中国人的行为数据是此模型中信息(负熵)的源头」这一事实。从信息学的角度,这个推荐模型,已经蕴含了非常广泛的中国人的行为数据。而这,我认为,是中国政府要明确禁止此类技术出口的根本原因所在。
问题4:如果出售了模型会怎么样?
这是一个自然的追问。尽管模型的负熵源自用户数据,但从模型并不能逆推还原出用户数据。所以即使把模型出售给外国企业又如何呢?又并不会导致隐私数据外泄。
我认为这个问题会暴露出我们在看待「数据安全」这个议题时的一种传统而局限的视角。美国的棱镜计划已经让我们看到,传统意义上的「隐私数据外泄」——例如知道某个人的姓名年龄信用卡号——并不是用数据为恶的必要条件:只要收集和分析大量人群的通信元数据(即:哪个设备和哪个设备通信),并不需要了解通信的具体内容,就可以对「具有威胁的」个体进行精确定位和打击。
TikTok这个例子则会把我们的思路再往前推一步:只要掌握大量人群行为的模型,并不需要掌握具体的行为数据,就可以对整个人群进行精确定位和打击。举例来说,如果CIA想发布一个攻击中国政府的信息,过去它需要咨询了解目标受众的专家,根据专家的建议调整讲述这条信息的方式;如果有了字节跳动的推荐引擎和模型,它就可以用各种风格来编写这条消息,然后丢给推荐引擎来评分,判断哪种风格更可能受中国读者欢迎、甚至更受中国某个细分群体的欢迎。蕴含广泛中国人行为数据的推荐模型,几乎立即就可以用作舆论战的武器。
一切负熵俱有由来。
一切负熵俱有能量。
所以,中国政府紧急调整《目录》限制TikTok的出售,很可能,并不只是为了避免民营企业家抱薪救火,而是可能有更紧迫的国家安全角度的考量。
问题5:这个案例有何历史意义?
我甚至有种感觉,站在不远的将来往回看,TikTok这个案例,有可能具有里程碑式的历史意义。因为这个案例让我们重新反思一个非常重要而又非常现实的问题:
在大数据时代,网络战场的边界在哪里?
TikTok的案例告诉我们,如果一个国家想在网络战场上攻击另一个国家,不一定需要黑破它的防火墙,不一定需要窃取它的隐私数据,甚至不一定需要拿到它的任何数据库。只要通过企业并购获得某种基于机器学习的「个性化服务技术」,就有可能对后者展开攻击。
我不知道这场战争是否已经打响。但很明显,打响这场战争需要的武器,并不难造。认识到这种武器存在的可能性,也许在不远的将来,会被证明是一个重要的历史节点。
文章来源:程序员练功房 作者:熊节
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者Cashcow
隐私已经死去,软件正在吃掉世界,数据即将爆炸


















