
意义远超阿法狗:DeepMind用足球撬开物理世界的人工智能
如果说谷歌旗下人工智能公司DeepMind用围棋AI击败人类世界冠军宣告了人工智能第三次浪潮的到来,那么,足球就是DeepMind开启智能机器人时代的那把钥匙。
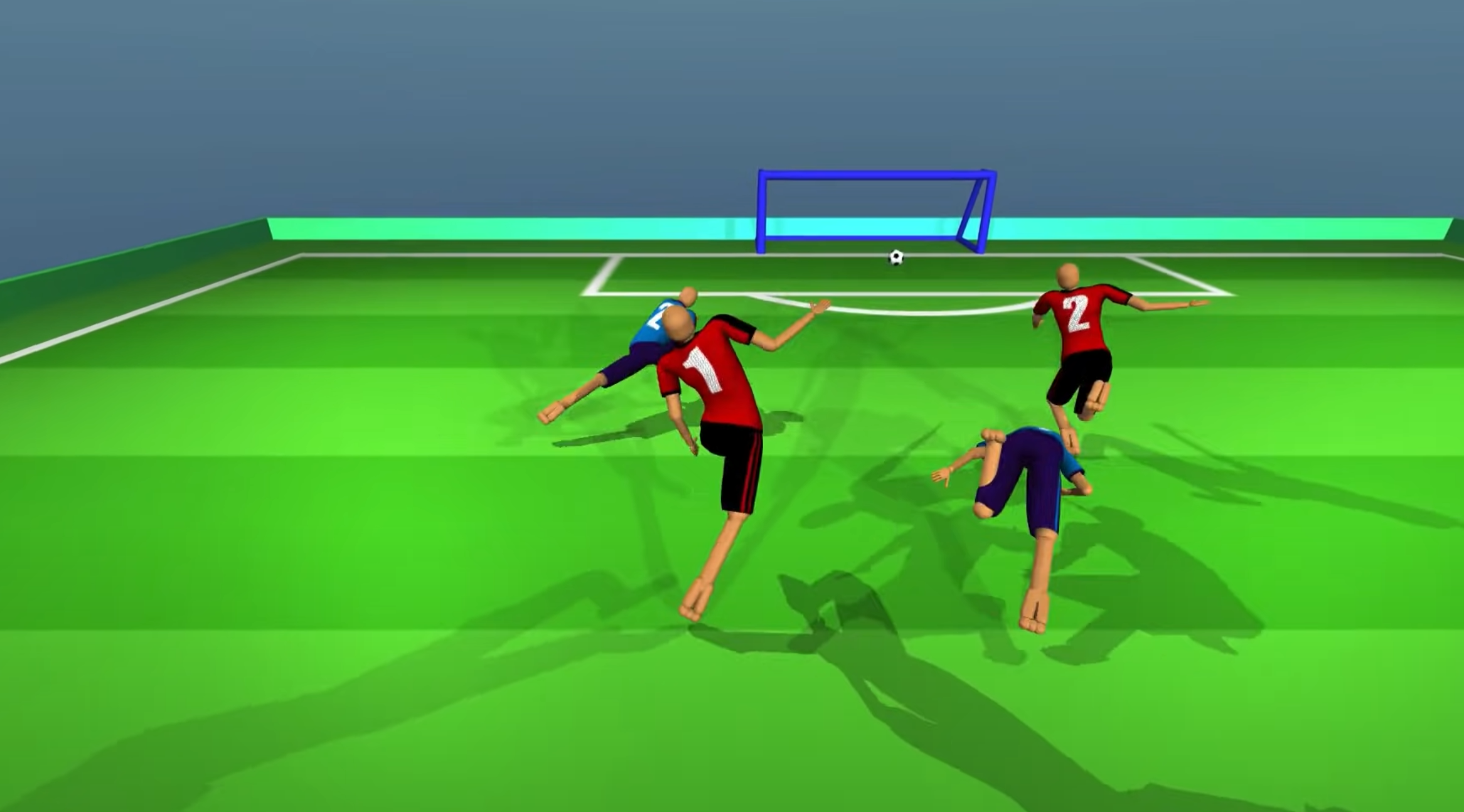
近日,DeepMind发布了一个看似怪异的人工智能踢球视频(下图),视频中几个虚拟机器人在室内足球场地激烈拼抢,虽然动作看上去有些别扭,但是作为业余足球爱好者的作者还是被深深地震撼到了。因为虚拟机器人们显然已经通过大量训练掌握了盘带、传球、防守、射门等基本个人足球技巧和团队配合“意识”。
如何踢出漂亮的团队足球?这是很多国家数十年都未能实现的梦想,因为足球太复杂太困难了,即便对于专业足球运动员来说也是如此,更何况是过马路都费劲的机器人。因此,DeepMind选择用足球游戏训练人工智能适应这个物理世界不仅极具挑战性,同时也意义重大。如果说围棋是最烧脑的脑力游戏,那么足球就是最“吃算力”的体育运动,运动员不但要具备扎实的停球传球运球基本功,而且还要随时掌握并分析场上瞬息万变的态势,在一瞬间做出(个人或团队协作的)最佳预测和选择。
足球,也许是人类在物理世界中集体运动的天花板,足球是圆的,因此足球运动强调的对不确定性和随机性的掌控和预测也是人工智能以机器人形态进入人类社会所需要面临的最大挑战(虽然不会有足球比赛那么激烈,例如防御性驾驶)。
以目前人类机器人工程领域的技术能力,显然还远远不足以生产并训练出一个“梅西”,这个目标甚至在遥远的未来也无法实现。但是战胜人类球员并不是人工智能科学家的最终目的,正如两足机器人的奔跑速度超过博尔特一样,不值得炫耀。真正吸引人工智能科学家的,是足球运动承载着人类团队运动的艺术和智慧。仅仅对漂亮足球机制的人工智能学习,就足以推动智能机器人迈出走进物理世界的革命性的一大步。正如DeepMind在《科学机器人》杂志上发表的论文中所阐述的,发现漂亮足球的机制——从奔跑、带球等基础知识到团队合作的高阶概念——证明更具挑战性。DeepMind的论文可能看起来很无聊,但学习足球的基础知识有朝一日可以帮助机器人以更自然、更人性化的方式在我们的世界中移动。
“为了‘解决’足球问题,你必须在通向通用人工智能 (AGI) 的道路上实际解决许多未解决的问题,”DeepMind 的研究科学家 Guy Lever 说。“控制整个人形身体,协调——这对 AGI 来说真的很难——实际上掌握了低水平的运动控制和长期计划之类的东西。”
人工智能必须重新创造人类玩家所做的一切——甚至是我们不需要有意识地思考的事情,比如如何精确地运用每个肢体和每块肌肉处理移动中的球——每秒做出数百个决定。足球场上最基本的动作也需要极为复杂和精确的计算和控制,我们没有考虑就这样做,这对人工智能来说是一个非常困难的问题,我们并不确定人类究竟是如何做到这一点的。”Lever 说。
既然目前的物理机器人的运动能力远远无法满足模拟足球比赛的需要,DeepMind决定使用以真人为模型的虚拟人形机器人,这些虚拟机器人有 56 个关节点和受限的运动范围——这意味着它们无法像伊布拉希莫维奇那样将膝关节旋转到夸张的角度。首先,研究人员只是给虚拟机器人球员一个目标——例如跑步或踢球——然后通过大量训练和强化学习,让虚拟机器人尝试弄清楚如何到达目标,就像过去研究人员所做的那样教模拟类人机器人如何在复杂物理环境中通过障碍(那次训练得到了滑稽的结果,机器人的动作看上去就像抽搐的僵尸,下图:)。

“这并没有真正奏效,” DeepMind 研究科学家Nicolas Heess 说道,他与Lever是该论文的合著者。由于问题的复杂性、可用的选项范围广泛以及缺乏关于任务的先验知识,虚拟机器人们真的不知道从哪里开始——因此扭动和抽搐。
因此,Heess、Lever 及其同事使用了神经概率运动原语 (NPMP),这是一种将 AI 模型推向更像人类的运动模式的教学方法,期望这些基础知识将有助于解决如何在虚拟足球场周围移动。“它让你的运动控制看上去更像是现实的人类行为,”Lever 说。“这是从动作捕捉中学到的——捕捉真实人类球员的踢球动作。”
这“重新配置了行动空间,”Lever 说。虚拟机器人的运动受到它们模仿的人体关节的限制,只能以某些方式弯曲,来自真实人类的数据会进一步限制它们,这有助于简化问题。“它使有价值的东西更有可能通过反复试验被发现,”Lever 说。NPMP 加速了学习过程。在教人工智能以人类的方式做事的同时,给予它足够的自由度去自己去发现问题的解决方案,二者需要达成一个“微妙的平衡” 。
基础训练之后是单人训练:无球跑动、盘带运球,模仿人类学习足球的基础培训。强化学习的奖励是像在无球的情况下成功跟踪目标,或者将球运到靠近目标的地方。Lever 说,这种技能课程是完成日益复杂的任务的一种自然方式。
目的是鼓励虚拟机器人在足球环境中重用他们可能在足球环境之外学到的技能——在不同的运动策略之间进行总结和灵活切换。掌握这些技巧的机器人充当教练。就像鼓励人工智能模仿它从人类动作捕捉中学到的东西一样,新手机器人也因为没有偏离教练机器人在特定场景中使用的策略太远而得到奖励,至少在开始时是这样。“这实际上是在训练期间优化的算法参数,”Lever 说。“随着时间的推移,他们原则上可以减少对教练的依赖。”
训练好虚拟机器人球员后,就进入比赛训练阶段:从 2v2 和 3v3 比赛开始,以最大限度地提高机器在每轮模拟中积累的经验(类似业余爱好者的小场轮换比赛)。刚开始场面异常混乱,机器人球员们像公园里的狗群一样追逐足球,球员像醉汉一样跌跌撞撞地奔跑,进球全靠意外,不是通过助攻射门,而是墙面的幸运反弹。
在比赛训练中,研究人员只是给虚拟机器人球员设定了一个目标:进球获得奖励,但研究人员很快发现团队的合作等特性开始出现。“在训练开始时,所有机器人都只是傻乎乎跑向球,几天后的某个时候,我们看到机器人开始意识到“跑位”——当一名队友控球时,另外一个机器人会跑到空挡期待队友尝试射门或传球,”Lever 说。这是第一次在如此复杂且反应迅速的人工智能中看到这种协作和团队合作。“这是我感兴趣的突破之一,”Lever 说。
至于这一切的意义何在?Heess指出这不是要称霸机器人世界杯,而是将虚拟机器人学到的一些低级技能灌输到物理机器人中,以使它们在现实世界中以更“安全和自然”的方式移动。这不仅是为了避免吓到与它们互动的人类,而且还可以解决非结构化强化学习可能产生的紧张、不规则的运动,后者可能会损坏未经过适应性优化的机器人,或者只是浪费能量。
这都是“拟真智能”(embodied intelligence)工作的一部分——即通用人工智能可能需要以某种物理形式在世界各地移动,并且这种形式的属性可能决定它的行为方式。“这在模拟世界(越来越多地以基于物理的模拟为特色)和开发机器人学习方法方面都很有趣,”Heess 说。
最终,这些看上去像闹剧的虚拟机器人足球比赛可以帮助机器人及其在数字世界的虚拟版本以看起来更人性化的方式移动——即使他们也许永远不会在足球比赛中击败我们。“足球本身并不是真正的最终目标,”Lever 说:“像人类一样踢球对于人工智能来说欠缺的东西太多了。”
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者IT经理网
IT经理网(CTOCIO.com)是中国领先的精确定位并服务CTO/CIO决策者人群的高端IT媒体和职业交互平台。核心团队由分布在美国和中国的资深IT媒体人、企业管理专家和市场分析专家组成。


















